The Problem
An e-commerce business received supplier product catalogs as PDFs and unstructured emails every day. Employees spent 8+ hours daily manually reading these documents and typing product names, SKUs, pricing, dimensions, and specifications into Airtable.
This manual entry was not only exhaustive — it was error-prone. Typos and transcription mistakes in SKU numbers and pricing was causing fulfillment issues that cost the client money and led to customer complaints. The process scaled poorly: as the business grew, they needed to hire more people just to keep up with data entry.
- 8 hours/day of repetitive data entry by 2 full-time staff
- 5–10% error rate causing fulfillment problems
- 1–2 day lag between receiving catalogs and products available in the system
- Process did not scale — each new supplier required more headcount
The Solution
I built an end-to-end AI pipeline that monitors the client's supplier inbox, extracts structured data from any format (PDF, Excel, plain email), and automatically creates or updates Airtable records — all without human involvement for standard-confidence extractions.
The pipeline handles two document types with different parsers:
- PDF Catalogs: Processed by a Python Cloud Function that extracts all text and tables, then structured by GPT-4
- Email catalogs: HTML/text parsed directly in Make.com, then sent to GPT-4 for structured extraction
"The system now processes an entire supplier catalog — 200+ products — in under 4 minutes.
What took two people all day is now completely automated."
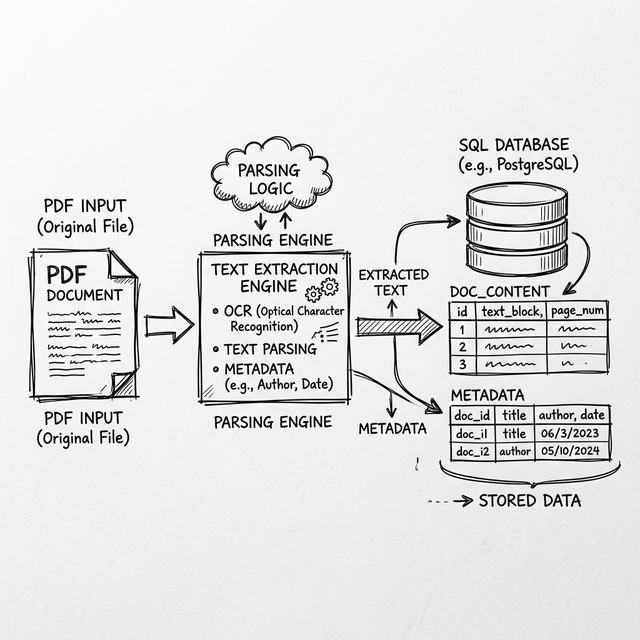
Technical Architecture
The Results
- 8+ hours/day of manual data entry completely eliminated
- 500+ product records processed daily without human input
- Extraction accuracy: 97%+ (vs. 90–95% with manual human entry)
- Low-confidence extractions (under 85% confidence) routed to a human review queue — only ~3% of records require any human check
- Catalog-to-system lag reduced from 1–2 days to under 10 minutes